Getting Started with Julia for Actuaries

This article also appears on JuliaActuary.org. It can be found here: Getting Started with Julia for Actuaries | JuliaActuary
The previously published article titled “Julia for Actuaries” gave a longer introduction to why Julia works so well in actuarial workflows. In summary: Julia's attributes are "evident in its pragmatic, productivity-focused design choices, pleasant syntax, rich ecosystem, thriving communities, and its ability to be both very general purpose and power cutting edge computing."
This is the second in the following trilogy of article topics:
- Why Julia works so well for actuaries
- basic tooling and general packages of interest, and
- actuarial-specific packages.
Reminder of Why Julia?
In the 2021 Stack Overflow Survey, Julia was the 5th most loved language. This was ahead of other languages commonly used in actuarial contexts, such as Python (6th), R (28th), C++ (25th), Matlab (36th), or VBA (37th).
There are three main reasons to consider using Julia:
- The language itself offers expressiveness, pleasant syntax, and less boilerplate than many alternatives. Multiple dispatch is a programming paradigm that is an evolution of object-oriented approaches that's more amenable to a wide range of programming styles, including functional and vectorized approaches. It affords Julia code a high level of composability and is what makes the Julia ecosystem so powerful.
- High performant Julia code, instead of needing libraries written in C/Cython/etc. For lots of problems, especially "toy" problems as you learn a language, the speed of Matlab/Python/R is fast enough. However, in real usage, particularly actuarial problems, you might find that when you need the performance, it's too late.[1]
- The language, tooling, and ecosystem is very modern, mature, and powerful. A built-in package manager, packages that work together without needing to know about each other, differentiable programming, meta-programming (macros), first-class GPU/parallel support, and a wide range of packages relevant to actuarial workloads.
More detail of why Julia works so well in actuarial contexts was discussed in the prior article, “Julia for Actuaries.” The rest of this article is going to focus on getting oriented to using Julia, and the next article in the series will introduce actuarial packages available.
The Language Itself
Julia is a high-level language, with syntax that should feel familiar to someone coming from R, Python, or Matlab. This article is too short for a true introduction to the language. Fortunately, there's a ton of great references online, such as:
Julia code is compiled on-the-fly, generating efficient code for the specific data that you are currently working with. This is kind of an in-between of a fully interpreted language (like pure Python or R) and a complied language like C++ which must compile everything in advance.
Born of a desire to have the niceties of high-level languages with the performance of low-level compiled code, there are many built-in data structures and functions related to numerical computing like that used in finance, insurance, and statistics.
If you just want a quick introduction for beginners, Julia For Data Science is a great resource with easy, digestible tutorials. If you want a ground-up introduction, the e-book Think Julia starts simple and builds up. If you prefer to learn-by-example: the interactive, free, online course Introduction to Computational Thinking by MIT will have you working on everything from data science to climate modeling.
Lastly, JuliaAcademy.com has a number of free courses that introduce the language via data science, machine learning, or "for nervous beginners."
Spotlight on Features
A full introduction to the language is beyond the scope of this article. There are two features we'd like to highlight here, which exemplify powerful features not available in other languages. These might sound a little technical at first, but as Paul Graham describes in his essay, “Beating the Average,” it is hard to see what you might be missing until you get experience with it.
Multiple Dispatch
Multiple dispatch is the term for deciding which function to call based on the combination of arguments. Taking an example pointed out by data scientist Brian Groenke[2] of a simple ordinary least squares implementation:
ols(x,y) = inv(x'x)x'y
# alternatively, one can write this using matrix division:
ols(x,y) = x \ y
"This very naive implementation already works for any appropriately sized x and y, including the multivariate case where x is a matrix or multiple-target case where y is a matrix. Furthermore, if x and y have special types (e.g., diagonal or sparse matrices), we get the potentially optimized implementations (of the different combinations) for free."
In a language without multiple dispatch, the alternative would be to:
- Define ols for every combination of types you might encounter, and
- attach a method to a class with every combination of second argument type.
The statistician Josh Day wrote an entire blog post about how multiple dispatch boosts one's productivity, allows for less code, and more time spent on solving the actual problem at hand.
Meta-programming and Macros
Meta-programming is essentially the ability to program the language itself, and macros are one of the tools that provide this ability. In the Paul Graham essay mentioned above, macros are an example of the competitive advantage conferred by a more powerful language.
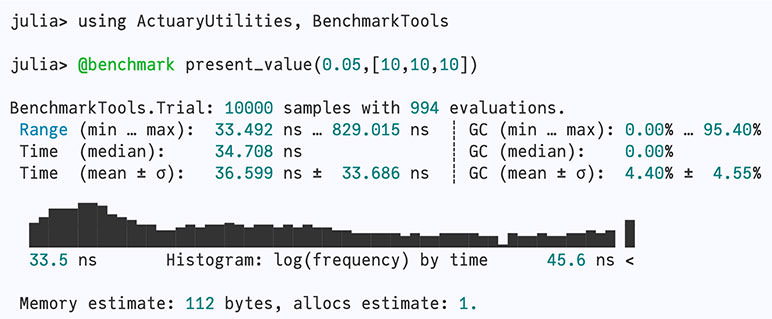
For example, when you see @benchmark present_value(0.05, [10, 10, 10]) in Julia, the @benchmark is a macro (starts with @). It modifies the written code to wrap present_value in setup, timing, and summary code before returning the result of present_value. There is an example of this later in the article.
Most other languages don't have macros, and it means that it's hard to “hook into” code in a safe way. For example, benchmarking can involve a lot of boilerplate code just to setup, time, and summarize the results (such as the timeit library in Python).[3]
Note that using macros is quite prevalent when coding in Julia, however writing macros is more advanced usage and beyond the scope of a "getting-started" guide.
Installation and Tooling
Installation
Julia is open source and can be downloaded from JuliaLang.org and is available for all major operating systems. After you download and install, then you have Julia installed and can access the REPL, or Read-Eval-Print-Loop, which can run complete programs or function as powerful day-to-day calculator. However, many people find it more comfortable to work in a text editor or IDE (Integrated Development Environment).
If you are looking for managed installations with a curated set of packages for use within an organization, there are ways to self-host package repositories and otherwise administratively manage packages. Julia Computing offers managed support with enterprise solutions, including push-button cloud compute capabilities.
Package Management
Julia comes with Pkg, a built-in package manager. With it, you can install packages, pin certain versions, recreate environments with the same set of dependencies, and upgrade/remove/develop packages easily. It's one of the things that just works and makes Julia stand out versus alternative languages that don't have a de-facto way of managing or installing packages.
Package installation is accomplished interactively in the REPL or executing commands.
- In the REPL, you can change to the Package Management Mode by hitting ] and, e.g., add DataFrames CSV to install the two packages. Hit [backspace] to exit that mode in the REPL.
- The same operation without changing REPL modes would be: using Pkg; Pkg.add(["DataFrames", "CSV"])
Related to packages, are environments which are self-contained workspaces for your code. This lets you install only packages that are relevant to the current work. It also lets you “remember” the exact set of packages and versions that you used. In fact, you can share the environment with others, and it will be able to recreate the same environment as when you ran the code. This is accomplished via a Project.toml file, which tracks the direct dependencies you've added, along with details about your project like its version number. The Manifest.toml tracks the entire dependency tree.
Reproducibility via the environment tools above is a really key aspect that will ensure Julia code is consistent across time and users, which is important for financial controls.
Editors
Because Julia is very extensible and amenable to analysis of its own code, you can typically find plugins for whatever tool you prefer to write code in. A few examples:
Visual Studio Code
Visual Studio Code is a free editor from Microsoft. There's a full-featured Julia plugin available, which will help with auto-completion, warnings, and other code hints that you might find in a dedicated editor (e.g., PyCharm or RStudio). Like those tools, you can view plots, search documentation, show datasets, debug, and manage version control.
Notebooks
Notebooks are typically more interactive environments than text editors—you can write code in cells and see the results side-by-side.
The most popular notebook tool is Jupyter (Julia, Python, R). It is widely used and fits in well with exploratory data analysis or other interactive workflows. It can be installed by adding the IJulia.jl package.
Pluto.jl is a newer tool, which adds reactivity and interactivity. It is also more amenable to version control than Jupyter notebooks because notebooks are saved as plain Julia scripts. Pluto is unique to Julia because of the language's ability to introspect and analyze dependencies in its own code. Pluto also has built-in package/environment management, meaning that Pluto notebooks contains all the code needed to reproduce results (as long as Julia and Pluto are installed).
A Whirlwind Tour of General-Purpose Packages
The Julia ecosystem favors composability and interoperability, enabled by multiple dispatch. In other words, because it's easy to automatically specialize functionality based on the type of data being used, there's much less need to bundle a lot of features within a single package.
As you'll see, Julia packages tend to be less vertically integrated because it's easier to pass data around. Counterexamples of this in Python and R:
- Numpy-compatible packages that are designed to work with a subset of numerically fast libraries in Python;
- special functions in Pandas to read CSV, JSON, database connections, etc.; and
- the Tidyverse in R has a tightly coupled set of packages that works well together but has limitations with some other R packages.
Julia is not perfect in this regard, but it's neat to see how frequently things just work. It's not magic, but because of Julia features outside the scope of this article it's easy for package developers (and you!) to do this.
Julia also has language-level support for documentation, so packages can follow a consistent style of help-text and have the docs be auto-generated into web pages available locally or online.
The following highlighted packages were chosen for their relevance to typical actuarial work, with a bias toward those used regularly by the authors. This is a small sampling of the over 6,000 registered Julia Packages.[4]
Data
Julia offers a rich data ecosystem with a multitude of available packages. Perhaps at the center of the data ecosystem are CSV.jl and DataFrames.jl. CSV.jl is for reading and writing text files (namely CSVs) and offers top-class read and write performance. DataFrames.jl is a mature package for working with dataframes, comparable to Pandas or dplyr.
Other notable packages include ODBC.jl, which lets you connect to any database (given you have the right drivers installed), and Arrow.jl which implements the Apache Arrow standard in Julia.
Worth mentioning also is Dates, a built-in package making date manipulation straightforward and robust.
Check out JuliaData for more packages and information.
Plotting
Plots.jl is a meta-package providing an interface to consistently work with several plotting backends, depending if you are trying to emphasize interactivity on the web or print-quality output. You can very easily add animations or change almost any feature of a plot.
StatsPlots.jl extends Plots.jl with a focus on data visualization and compatibility with dataframes.
Makie.jl supports GPU-accelerated plotting and can create very rich, beautiful visualizations, but its main downside is that it has not yet been optimized to minimize the time-to-first-plot.
Statistics
Julia has first-class support for missing values, which follows the rules of three-valued logic so other packages don't need to do anything special to incorporate missing values.
StatsBase.jl and Distributions.jl are essentials for a range of statistics functions and probability distributions respectively.
Others include:
- Turing.jl, a probablistic programming (Bayesian statistics) library, which is outstanding in its combination of clear model syntax with performance.
- GLM.jl for any type of linear modeling (mimicking R's glm functionality).
- LsqFit.jl for fitting data to non-linear models.
- MultvariateStats.jl for multivarate statistics, such as PCA.
You can find more packages and learn about them here.
Machine Learning
Flux, Gen, Knet, and MLJ are all very popular machine learning libraries. There are also packages for PyTorch, Tensorflow, and SciKitML available. One advantage for users is that the Julia packages are written in Julia, so it can be easier to adapt or see what's going on in the entire stack. In contrast to this design, PyTorch and Tensorflow are built primarily with C++.
Another advantage is that the Julia libraries can use automatic differentiation to optimize on a wider range of data and functions than those built into libraries in other languages.
Differentiable Programming
Sensitivity testing is very common in actuarial workflows: essentially, it's understanding the change in one variable in relation to another. In other words, the derivative!
Julia has unique capabilities where almost across the entire language and ecosystem, you can take the derivative of entire functions or scripts. For example, the following is real Julia code to automatically calculate the sensitivity of the ending account value with respect to the inputs:
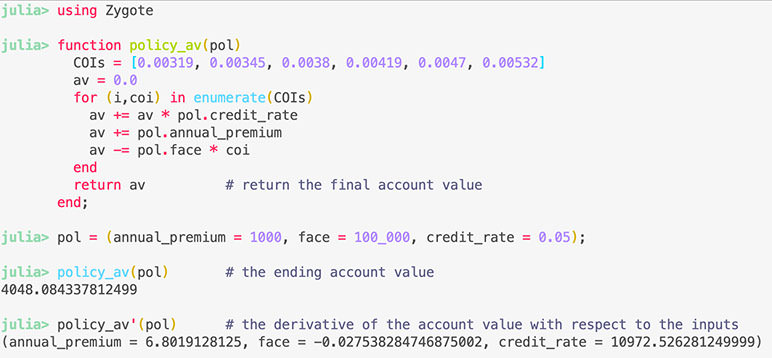
When executing the code above, Julia isn't just adding a small amount and calculating the finite difference. Differentiation is applied to entire programs through extensive use of basic derivatives and the chain rule. Automatic differentiation, has uses in optimization, machine learning, sensitivity testing, and risk analysis. You can read more about Julia's autodiff ecosystem here.
Utilities
There are also a lot of quality-of-life packages, like Revise.jl which lets you edit code on the fly without needing to re-run entire scripts.
BenchmarkTools.jl makes it incredibly easy to benchmark your code - simply add @benchmark in front of what you want to test, and you will be presented with detailed statistics. For example:
Test is a built-in package for performing testsets, while Documenter.jl will build high-quality documentation based on your inline documentation.
ClipData.jl lets you copy and paste from spreadsheets to Julia sessions.
Other Packages
Julia is a general-purpose language, so you will find packages for web development, graphics, game development, audio production, and much more. You can explore packages (and their dependencies) at https://juliahub.com/.
Actuarial Packages
Saving the best for last, the next article in the series will dive deeper into actuarial packages, such as those published by JuliaActuary for easy mortality table manipulation, common actuarial functions, financial math, and experience analysis.
Getting Help
Aside from the usual StackOverflow, there is a community page with links to the Discourse forum, Slack, and Zulip. The latter two have a dedicated #actuary channel.
Summary
This article introduced Julia, getting setup with running and editing, and pointed toward a number of general-purpose features and packages useful to actuaries. The next article in the series will focus on the range of actuarial-specific packages available.
Statements of fact and opinions expressed herein are those of the individual authors and are not necessarily those of the Society of Actuaries, the newsletter editors, or the respective authors’ employers.