Approaches to improve understanding, control and efficiency
By Arthur F. Heezen III
Financial reporting stakeholders can gain additional insight into reporting and related processes by borrowing the bag-of-words model from Natural Language Processing (NLP) and applying it to general ledger journal entries. Using this model, pairs of journal entries can be modeled and compared for similarity. This enables:
- Clustering of similar journal entries to help understand patterns,
- Visualizing the full range of activity in the general ledger,
- Machine learning to automatically classify journal entries for process management,
- Determining topics or themes in journal entries,
- Identification of unusual entries in support of auditing and analysis,
- Development of search tools to improve operating efficiency, and
- Process mining to discover and manage task interdependencies.
Journal Entry Primer
Although it predates computing platforms, double-entry accounting forms the foundation of modern financial systems. In this framework, the journal entry is a related set of adjustments to account balances. Each entry must consist of two or more detail lines, yielding the double-entry terminology. Each line identifies an account and an amount, which can be debits (positive) or credits (negative). When totaled across a journal entry, the amounts must net to zero (be debit-credit equal).
Additional journal entry attributes include date at which the balance should be adjusted, the date and time the entry was made and who entered it. Additionally, systematic workflows typically capture the data and time the entry was approved and by whom.
Accounts balances are typically maintained as part of a multi-dimensional data model. Thus, detail lines will usually have identifiers for various legal entities or companies, lines of business, funds and related information suitable to the organization. Journal entry detail lines must include at least all the attributes associated with balances. In practice there can be much more supplemental information.
Bag-of-Words Model
A basic and common approach to NLP is the bag-of-words model. This model represents documents by the count of words, or terms. Documents can be text of any length, from a phrase to a complete book. For example:
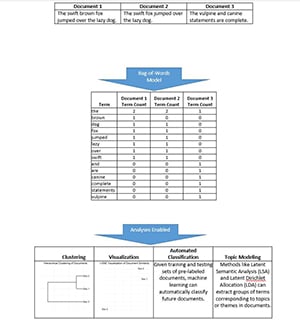
Feature Engineering and the Bag-of-Words
A pragmatic approach surrounds the bag-of-words model. As experience accumulates, researchers have encountered and surmounted challenges by tweaking the model. More generally in machine learning, both the bag-of-words model and adjustments are examples of feature engineering, which aims to develop variables useful for modeling.
Common feature engineering methods used with the bag-of-words model follow.
- Dimension Reduction: The bag-of-words model creates a high-dimensionality representation of documents. A very long document or a large corpus (collection of documents) can easily have tens or hundreds of thousands of unique words. Large numbers of dimensions create a challenge for many techniques. Sometimes low-frequency terms will be omitted, or other dimension-reducing methods, like Principle Components Analysis, are used to simplify analysis.
- Term Frequency: Long documents will have higher total counts, making them hard to compare to short documents. The term frequency (relative proportion of counts in the document) circumvents this problem.
- Stop Words and IDF: Words such as “the” will occur frequently in almost every document and, thus, have very low analytical value. NLP considers these stop words—sometimes they are simply omitted. Another approach is to reduce term frequency by a factor related to the proportion of documents having the term, which is called the Inverse Document Frequency (IDF).
- Term Order: The bag-of-words model does not preserve the original order of words. The order-less quality leads to the terminology of “bag.” For NLP this is sometimes a problem, and various adjustments are made to compensate. For example, bigrams (ordered pairs of words) are counted in addition to individual words.
Journal Entries as a Simple Bag of Accounts
Combining the concept of a journal entry and a bag-of-words model yields a representation that is useful for a range of analytics. Consider these entries:
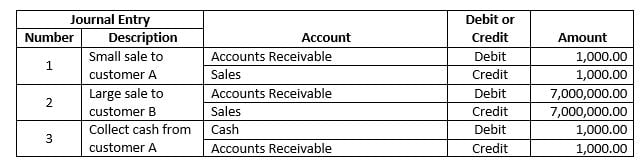
A very direct translation of the bag-of-words model to accounts yields this representation:
Simple Bag of Accounts
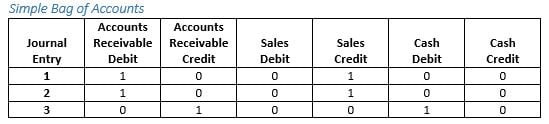
Within this representation journal entries 1 and 2 would appear as identical and neither would have anything in common with journal entry 3.
Feature Engineering with the Bag of Accounts
Remember that the bag-of-words model is modified as required to make it useful, and we call that process feature engineering. Here, we examine possible modifications to the basic bag-of-accounts model.
Consider if we wanted to detect that journal entries 1 and 2 are similar, but not label them as identical. One approach would be to use the amount of the corresponding journal entry line instead of the line count. The deficiency with this approach is that by comparison to a $7,000,000 line, a $1,000 line would be judged as non-equal just by magnitude. This is circumvented by using a base-10 logarithm of the amount. To prevent negative amounts one is added to the amount prior to taking the log.
Bag of Accounts with Logs of Amount
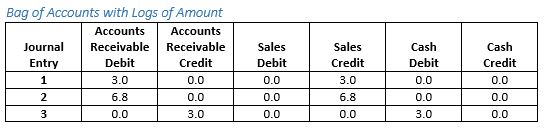
Now, journal entries 1 and 2 would be similar, but not identical. Both continue to have no relationship to journal entry 3.
If we wish to detect the connection between journal entries 1 or 2 and journal entry 3 via the Accounts Receivable account, we can add additional features that do not distinguish between debits and credits.
Bag of Accounts with Logs of Amount and Absolute Accounts
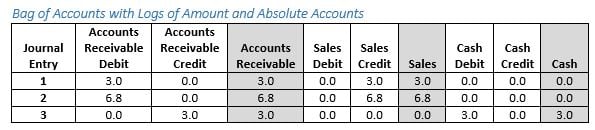
Some people might object to this addition of redundant information, since it violates the principle of parsimony. However, in the world of machine learning, this is normal, especially for nonlinear learning methods. The process typically starts with an all-inclusive set of possible features, allowing the learning algorithm to cull information with no marginal predictive value.
Conclusion
We have examined the basic bag-of-words model and reviewed some corresponding feature engineering. Also, we covered the basic structure of journal entries and a few ways they can be represented in a bag-of-accounts model. The next steps are to use this model for the analyses mentioned.
The bag-of-words model, originally developed for NLP, has been used in market basket analysis and image processing. The application of this model to financial systems demonstrates the boundless possibilities for quantitative disciplines.
Arthur F. Heezen III is director of Data Services at Torchmark Corporation. He can be contacted at afheezen@torchmarkcorp.com.