Surrogate Models: A Comfortable Middle Ground?
By Harrison Jones and Selina Chen
Predictive Analytics and Futurism Section Newsletter, August 2021

Surrogate models[1] are used for the purpose of model explainability, approximating the predictions from a complex model. In other words, a surrogate can be used to help with explaining the results of a black-box, a model which has higher predictive power but is difficult to interpret. It is possible to take this one step further and use the surrogate as a model in its own right. On the surface, this is a compelling option: the power of a black-box model with the benefit of model explainability.
In this article we will examine the benefits and drawbacks of using a global surrogate of a black-box model. Will the global surrogate still provide all the predictive power of the black-box model? Can we say with confidence that the model is sufficiently explained? Are surrogates a comfortable middle ground that provide insurers with the best of both worlds? We will ground this discussion through a fairly common example, pricing in auto insurance using data from the R package CASdatasets.
Global Surrogate Models
The process of building a global surrogate model on top of a machine learning black-box can be broken down into three steps:
- Train a black-box model of choice fi using underlying data Di.
- Select a new dataset Dj[2] and calculate the predictions from the black-box model fi. The predictions are denoted pˆj.
- Train an interpretable model fj using the dataset Dj as predictors and the predictions pˆj as the target variable. The trained model fˆj , is the surrogate.
Pros and Cons
Pros
First, the biggest advantage to building a surrogate model is the flexibility to choose any statistical framework that works for the modeler or the business. That can mean a decision tree, linear regression, generalized linear model (GLM), or anything else that meets the modeling need. As a by-product, one can choose a model that is easier to explain (i.e., with interpretable coefficients) or perhaps a framework that fits an alternative need of the business.
Second, surrogate modeling is straight-forward and easy to implement. As shown in the steps above, the process only requires fitting two models and there are no complex data manipulation steps. It is easy to describe the process to people who are not familiar with data science.
Lastly, the technique can provide interpretable and explainable results. For example, by choosing a regression-based model, one can easily show the relationships between the input variables and the target variable.
Cons
First, when building a surrogate, the user should be aware that this is a model trained on another model. The surrogate model does not have access to the actual observations and can only be as good as the black-box model. It is possible to stray farther from the real-world and lose predictive power. This is why a separate testing data set is crucial—it validates whether the loss of predictive power is significant.
Second, there is no clear definition of a good surrogate model. The measurement of surrogate performance requires judgment and there is no one-size-fits-all metric. It may be difficult to determine whether the surrogate model accurately approximates the black-box model.
Lastly, the surrogate model can have varying levels of performance for different subsets of the data. That is, it can closely approximate the results for one subset of the data, but be inaccurate for another subset of the data. This will cause the surrogate to be only partially interpretable.
Real-world considerations
Implementation
When we say “implementation,” we mean the task of pushing an actuarial model into a production environment that supports a business activity. In our example of auto insurance pricing, implementation would mean pushing the actuarial model into the policy admin software (which in turn interacts directly with consumers and/or brokers). In some cases, policy admin software is easy to configure for GLMs, since it already has the setup needed from previous executions of the rating framework.[3] For many insurers, implementing a machine learning model is still a difficult task. It often requires additional infrastructure and technical expertise. Since a surrogate model can take any statistical form, this offers insurers the flexibility to choose the form that works best for them.
Regulation and Unfair Discrimination
Regulators are tasked with protecting consumers, so that they are not unfairly discriminated. Regulations depend on the jurisdiction that insurance is sold, but common examples of unfair discrimination in insurance is pricing based on: Gender, race, or other socioeconomic factors. Black-box models could fail to show the exclusion of these discriminatory variables, which causes them to be met with hesitation by regulators. In theory, a surrogate could provide the model explainability that a regulator would be comfortable approving.
As a Complementary Model
A global surrogate model, as a means for intrepretability, is complementary to a black-box model regardless of whether the surrogate will end up being implemented. It can be dangerous for a business to use a black-box model without fully understanding the inner workings. There are countless examples of why it is a bad idea to push a model into a production environment without understanding the consequences.
Global Surrogate Example
The goal of this example is to build a case either for or against surrogate models. To do this we will construct a (simplified) example in the context of auto insurance pricing.[4] Through existing literature (Koenig (2020)) we are aware that other machine learning approaches can provide higher predictive power when compared to a traditional GLM in auto insurance pricing. So, we examine if using a GLM global surrogate of these machine learning approaches can/would do the following:
- Provide the same level of predictive power as black-box machine learning approaches.
- Provide a reasonable level of model explainability.
Data
The data being used for this example are called freMTPL2freq and freMTPL2sev and are pulled from the R package CASdatasets, see Dutang (2019). freMTPL2freq and freMTPL2sev contain frequency and severity data from French motor third-party liability policies. See Noll (2018) for full descriptions.
Approach
As mentioned previously, the goal of this example is to identify a case for or against using surrogate models in practice. To do this effectively we will generate three separate models to compare:
- A traditional GLM (denoted GLM),
- an xgboost model (denoted XGBoost), and
- a global surrogate GLM that is trained using predictions from xgb_base (denoted Surrogate).
We want to identify if the surrogate can obtain the same level of predictive power as XGBoost. If this is the case, then we would in theory have a more powerful model with the benefit of being easier to interpret.
Statistical Results and Interpretation
To measure model performance, we chose mean absolute error (MAE) and root mean squared error (RMSE) as key metrics. Both metrics measure the average magnitude of prediction errors and are indifferent to the direction of errors. MAE uses absolute difference, whereas RMSE takes square root of squared differences. For result interpretation, lower values imply better predictions.
The difference between the two metrics is that RMSE gives a higher weight to large errors. That is, RMSE penalizes the model for larger errors, and should be used when large errors are less favorable than small errors.
Table 1
Difference Between MAE and RMSE Metrics
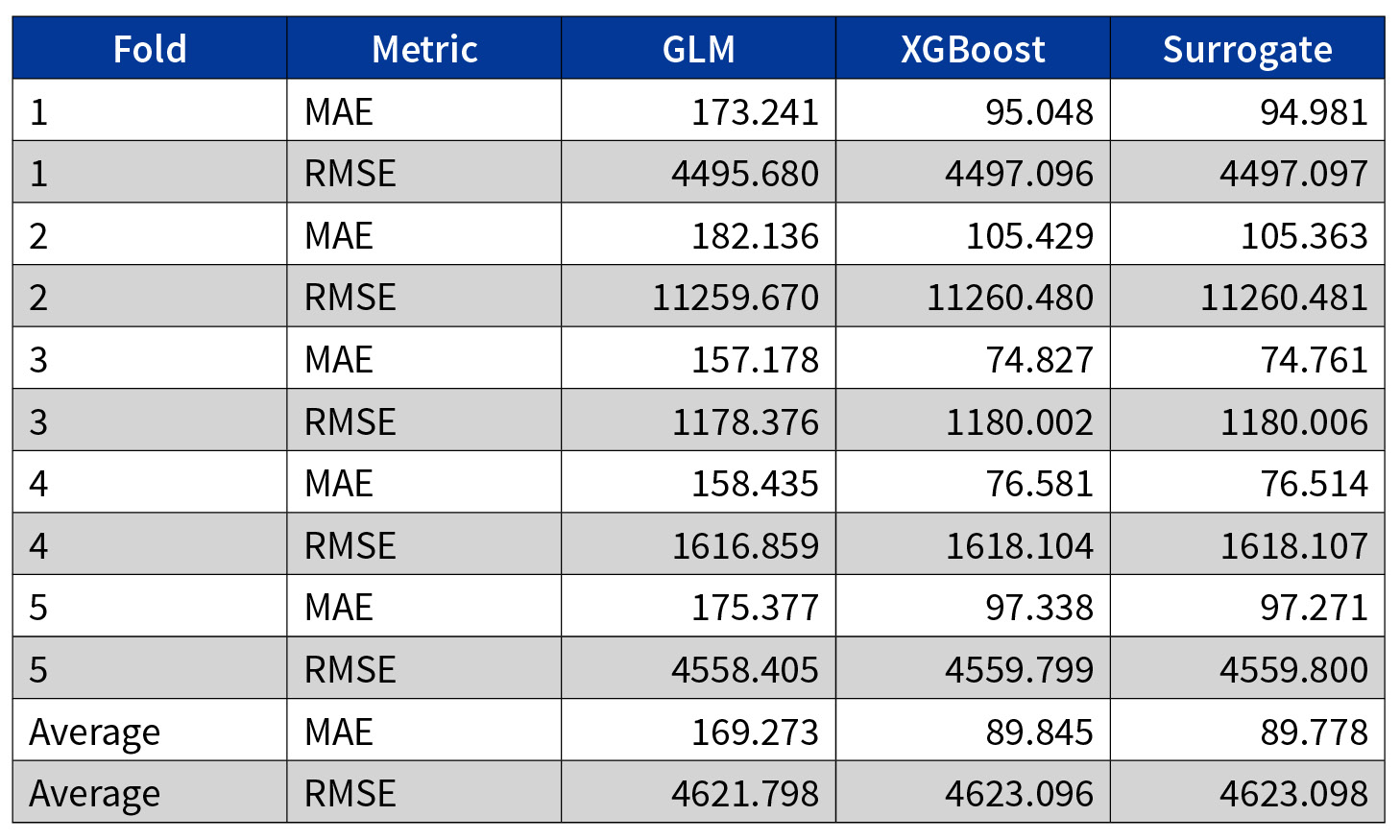
GLM Versus XGBoost
The two models produce similar RMSE, but XGBoost outperforms GLM on MAE. This suggests that XGBoost is better at predicting small errors. Given the focus of this article is to analyze the potential for surrogate models, we are comfortable with the model performance. However, it is important to note that XGBoost-based models generally can outperform GLMs. While that is not the case here, there are other articles that prove this and further the case for surrogates.[5]
XGBoost Versus Surrogate
The surrogate model has nearly identical prediction results when compared to the XGBoost model. This is an impactful result. It shows that a GLM can replicate the predictions of an XGBoost while providing explainability. This proves that a global surrogate can potentially be used as a complementary model that balances predictive power with explainability.
Conclusion
In this article, three models were developed, all of which built toward answering the question of whether global surrogate models could be used as a complement to powerful models that are difficult to interpret. What we have concluded is:
- Global surrogates could offer an alternative approach that provides both high predictive power and explainability; and,
- global surrogates are an option for insurers that have developed a black-box model that is difficult to implement, either due to regulatory constraints or other logistical issues.
Further research could be conducted in: Building an XGBoost version that produced better predictive results, whether global surrogate can “hide” predictor variables, and whether a similar (or better) application could be built using local interpretable model-agnostic explanations.
Statements of fact and opinions expressed herein are those of the individual authors and are not necessarily those of the Society of Actuaries, the newsletter editors, or the respective authors’ employers.
Harrison Jones, ASA, is a senior manager for Deloitte. He can be contacted at hajones@deloitte.ca. LinkedIn: https://www.linkedin.com/in/harrison-jones-a9947b60/
Selina Chen, ASA, CERA, is an associate actuary for Partner Re. She can be contacted at Selina.Chen@partnerre.com. LinkedIn: https://www.linkedin.com/in/cselina/