
Monitoring Machine Learning
By Carlos Brioso
Predictive Analytics and Futurism Section Newsletter, June 2021

Model monitoring is not a new topic, but it is surprisingly overlooked by data scientists and even business users. The main reason to monitor model performance is to ensure that the model is meeting business objectives. If not, it may be required to re-train or replace the model.
There are secondary reasons to monitor related to operational risk management. There are many things that go wrong or change while using a model. There are many new vendors in the market that are trying to approach model monitoring from different points of view as part of the machine leaning operations (MLOps) infrastructure. Navigating through the universe of offerings may be confusing; this article intends to give more clarity.
The implementation of a model can be thought to be very similar to the implementation of software. Software is usually deterministic. The focus of implementation testing ensures that calculations (the code) are correct. There are many applications that perform monitoring of software applications. These fall into the category of application monitoring tools (APM) that monitor, optimize and investigate application performance.
What is different about the implementation of a machine learning model? First, the model’s performance is expected to deteriorate over time. Second, the environment and behaviors surrounding the business problem may change making the model obsolete. Third, labels (realized values) may not be available for months or years to evaluate model performance; for example, a mortality model may require a few years to accumulate enough experience to evaluate its accuracy and discriminatory power.
Traditional Aspects of Model Monitoring
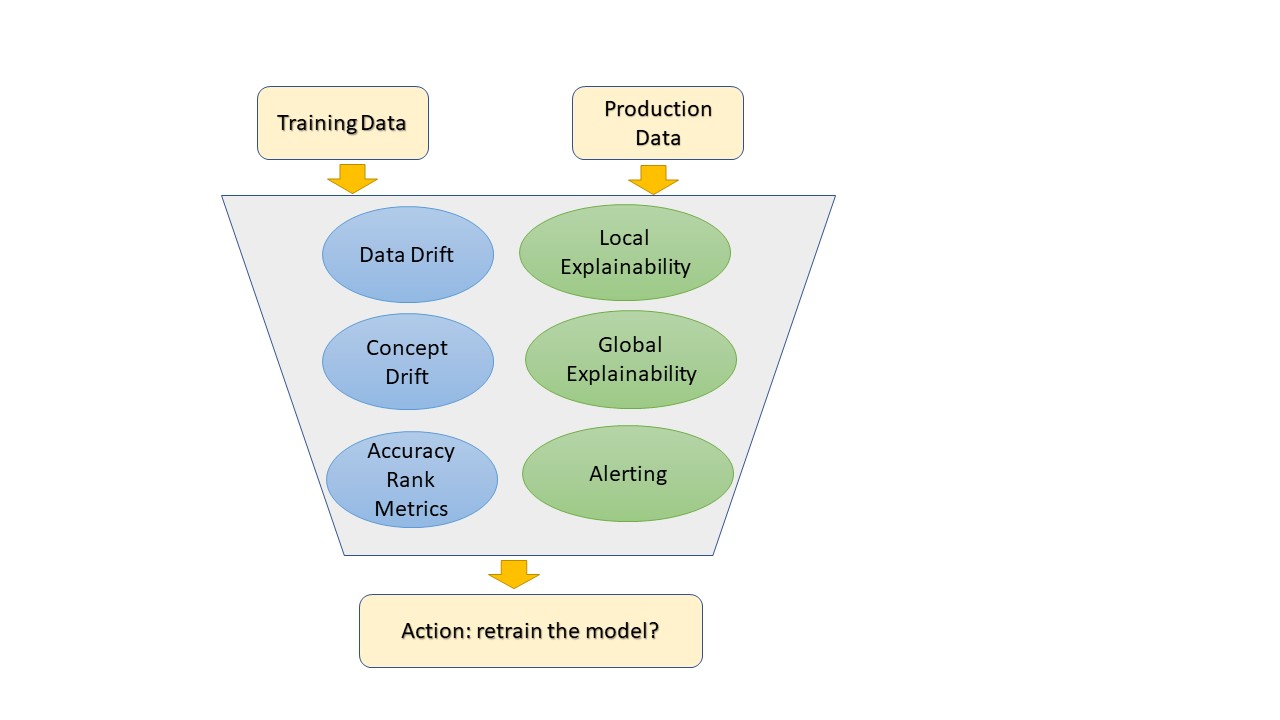
Data Drift and Concept Drift
These are leading indicators; they inform us how data is changing over time, but do not necessarily tell us that the performance of the model is deteriorating. Drift metrics intend to summarize how similar is the data used to develop the model (training) to the data being scored by the model (production). One popular metric is the population stability index (PSI) that has been used for many decades by practitioners in credit risk models.
Accuracy and Rank Metrics
These are traditional metrics that are found in any statistics book. Vendors usually provide a set of metrics for regression and classification models. Some metrics that have been paid less attention and are relevant to actuarial problems, are metrics that consider censoring in the observations (e.g., C-statistic for survival models).
New Aspects of Model Monitoring
Model Explainability
There are several methods developed in recent years to make the decisions of machine learning models understandable by humans. There are local and global interpretations. Local interpretation explains what factors influence an individual model prediction or decision. For example: A subject is assigned a high-risk mortality due to high blood pressure, BMI, etc. Global interpretation explains the variable importance in the model.
Model explainability is particularly important for models that are constantly retrained (dynamic models that are trained online) where there is less control and testing for each version of the model. For models that follow a strict development, validation and approval process, this is a less important aspect of monitoring since the model should be well understood before implementation.
Operational Performance
The implementation of machine learning models is like the implementation of software. There are operational aspects that should be considered. For example, when a threshold is crossed and action or investigation is needed, the monitoring system should send alerts to the appropriate parties for timely response, tracking the issue and recording the resolution process.
Another operational aspect is version control. When reviewing model decisions, it is important to know what version of the model was used, this is especially important for dynamic models. This makes structured use of a version control system (e.g., git) critical. (See Figure 1)
Figure 1
Version Control System
Conclusion
While model monitoring has always been important, it is even more important in the context of dynamic modelling. This also makes the problem more difficult. Fortunately, many machine learning platforms offer a model and data monitoring service. Structuring this process will avoid building “technical debt” and lead to robust and responsive model services in the future.
Statements of fact and opinions expressed herein are those of the individual authors and are not necessarily those of the Society of Actuaries, the editors, or the respective authors’ employers.
Carlos Brioso, FSA, CERA, is vice president for Global Atlantic Financial Group. He can be contacted at carlos.brioso@gafg.com.